
Over the past 3 years I have been studying social networks for health (e.g. public health campaigns, clinical conferences). I have been collaborating with clinicians and analysts across the world in this work, publishing some of the outputs in peer-reviewed journals as listed below, studying the content, influencers, components of tweets that could influence retweeting, commercial influences in conference tweeting, responses beyond the hashtag, and looking at hierarchy of tweeting. Some of these have been published already – e.g. most recently a paper with Muge Cevik and David Ong, available for a few more weeks in free full text. Look out for details of the remaining papers over coming months.  One area that I have been keen to explore, but have not been able to until now, is mapping older tweets and retweets. Twitter provides access to tweets and retweets over the past 10 days. Sometimes a network will take longer than 10 days to establish, at which point the data become difficult – or expensive – to extract. This blog explains how to extract older tweets and retweets manually so that they can be mapped well beyond the 10 day limit, using NodeXL. I have used the example of #CwPAMS (Commonwealth Partnerships for Antimicrobial Stewardship) following a request by Diane Ashiru. I have illustrated this using 30 tweets first, and then the retweets that followed. It would be possible with patience and time to map all the #CwPAMS tweets using this method.
One area that I have been keen to explore, but have not been able to until now, is mapping older tweets and retweets. Twitter provides access to tweets and retweets over the past 10 days. Sometimes a network will take longer than 10 days to establish, at which point the data become difficult – or expensive – to extract. This blog explains how to extract older tweets and retweets manually so that they can be mapped well beyond the 10 day limit, using NodeXL. I have used the example of #CwPAMS (Commonwealth Partnerships for Antimicrobial Stewardship) following a request by Diane Ashiru. I have illustrated this using 30 tweets first, and then the retweets that followed. It would be possible with patience and time to map all the #CwPAMS tweets using this method.
I am not a programmer – hopefully somebody reading this blog will be able to identify a simpler way to do this. Until then, there are a few hoops to jump through:
- Apply for a Twitter Developer account.
- Download Postman software. Follow the advice in Postman tutorials about how to access Twitter API using details provided on being approved for a Twitter Developer account.
- Go to Twitter advanced search and search for your required term, refining dates to focus in on the required period. Once you become familiar with Twitter advanced search you will be able to enter searches manually using the Twitter search box – for example I used the following term to search for the earliest #CwPAMS tweets: #CwPAMS since:2018-09-01 until:2018-10-31. Click the “Latest” tab to show all the tweets chronologically.
- Open up the individual tweets so that you can see the URL for the tweet: for the tweet shown below – the first #CwPAMS tweet – the URL is https://twitter.com/THETlinks/status/1055854080004947968. The 19 digit number at the end of the URL is the tweet ID. Each tweet and retweet has a unique number which allows social network analytical packages to identify the specific tweet or retweet. It is not possible to see the retweet ID without going back to the Twitter API, which is where things get complicated as described in step 6 below..

- Click through each of the tweets you plan to map and record the 19 digit tweet ID for each post. You can then import these tweets, regardless of age, into NodeXL, selecting the option “From Twitter TweetID list network”. The following map shows the first 30 CwPAMS tweets mapped (without retweets).

- To extract the retweet IDs for the first tweet, go to Postman, select the “GET” command and enter the following text: https://api.twitter.com/1.1/statuses/retweets/1055854080004947968.json?count=100 (do not click this link – it will not work – you need to copy it into the command line in Postman). You can see the 19 digit tweet ID in this GET command. You will need to change this 19 digit number for each tweet for which you’re extracting retweets. This will produce the output as follows:

- The text in the box provides all the information about retweets. You will see 19 digit tweet ID strings (both for the original tweet and subsequent retweets) – e.g. 1057870154422476801 – which is a retweet by Graeme Hood. Copy them into a list and you can then add them into the NodeXL. I did this quickly by copying and pasting the full text output from Postman into an Excel file, sifting and sorting to pick out the retweet IDs that were 19 characters long as follows: i. Search for “id_str” – e.g. if output from Postman is in column E type the following into D2 (without inverted commas) “=SEARCH(“id_str”,E2)”. ii. Sort by the result, focusing in on those lines where result starts with 10 (which is the position in the text that we’re looking for). iii. Pull out the retweet ID using Excel’s string function (MID) typing (without inverted commas) “=MID(E2,20,19)”. Repeat steps 6 and 7 for each of the 30 tweet IDs. In this way, in a few minutes I was able to collect all the required information about retweets from the 30 tweets.
- Add the retweet IDs to the NodeXL import, as well as the tweet IDs identified earlier. This gives the following map (30 tweeters plus all the retweeters):
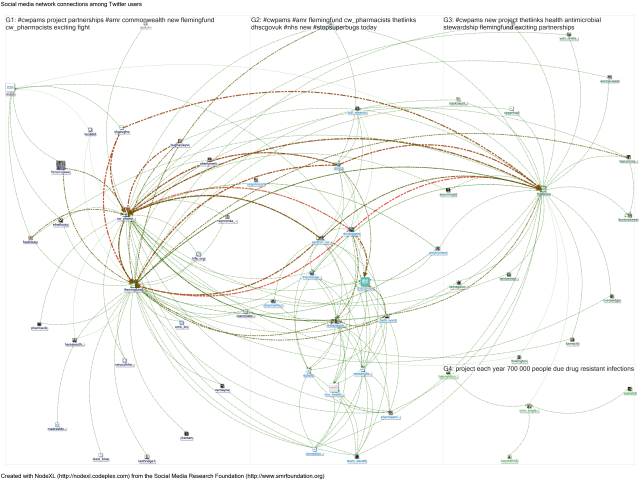
- This method works for tweets of any age, receiving up to 100 retweets per tweet. It is not perfect – e.g. I can’t see any record of Graeme Hood (the retweeter mentioned above in step 7) in the above map. However, it provides a way to salvage something useful where the 10 day limit has been exceeded
- Alternatives to NodeXL include TAGS, which is free, has an import by tweet and retweet ID function and has some mapping functions via its TAGSExplorer feature, but does not show as much detail about interactions as NodeXL.


Please get in touch if you have any ideas about automating this process.
Dr Graham Mackenzie, GPST1, Edinburgh, Scotland 13 December 2019.


Pingback: Taking a long-view of tweeting – an example looking at @HelenBevan’s account – #ScotPublicHealth