
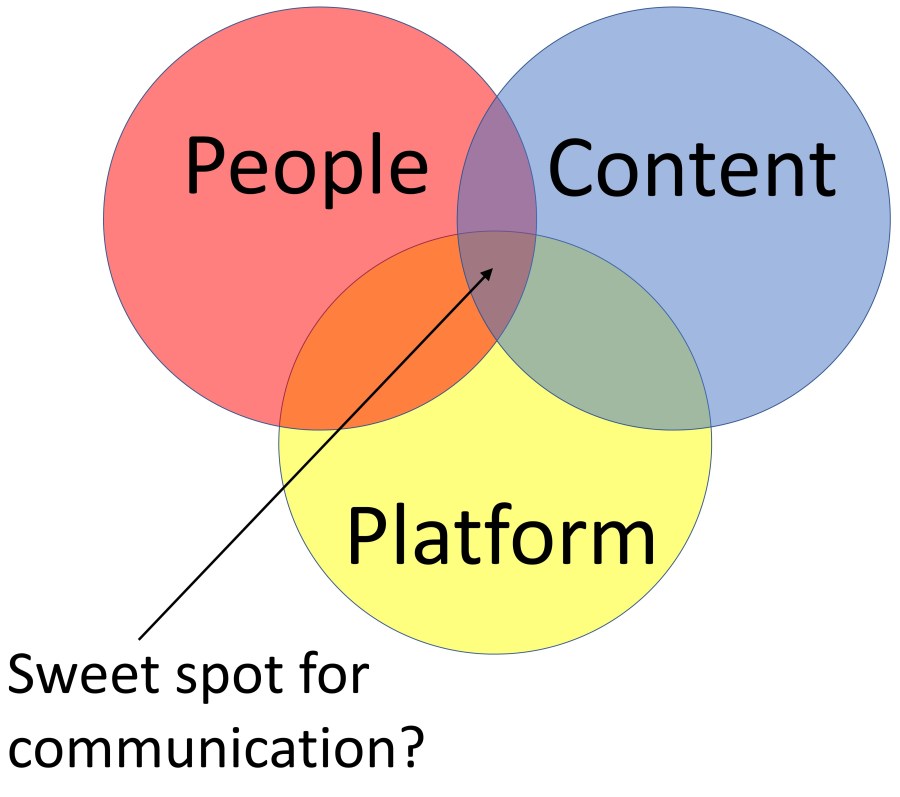
Scientific communication relies on clarity, specificity and universality. In this blog I explain how communication between medical tweeters is held back by a lack of clarity in hashtag choice, and by the absence of a “fuzzy search” feature in Twitter. I explore lessons from the way that medical research papers are categorised (MeSH headings) and propose options for improving medical tweeting, helping people to look beyond their usual social media bubble. I also demonstrate ways to visualise intentions vs reception for hashtags in two topical issues using word clouds.
I have written this as a blog, because I wanted to include a more reflective exploration of this topic than I could in a traditional medical paper. Hopefully, with the contribution of other medical tweeters, the ideas presented here can be developed into a peer reviewed paper in a medical journal.
